
We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a “lazy” fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder’s runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10× speedup for typical user interactions, where the editing mask represents 10% of the image.
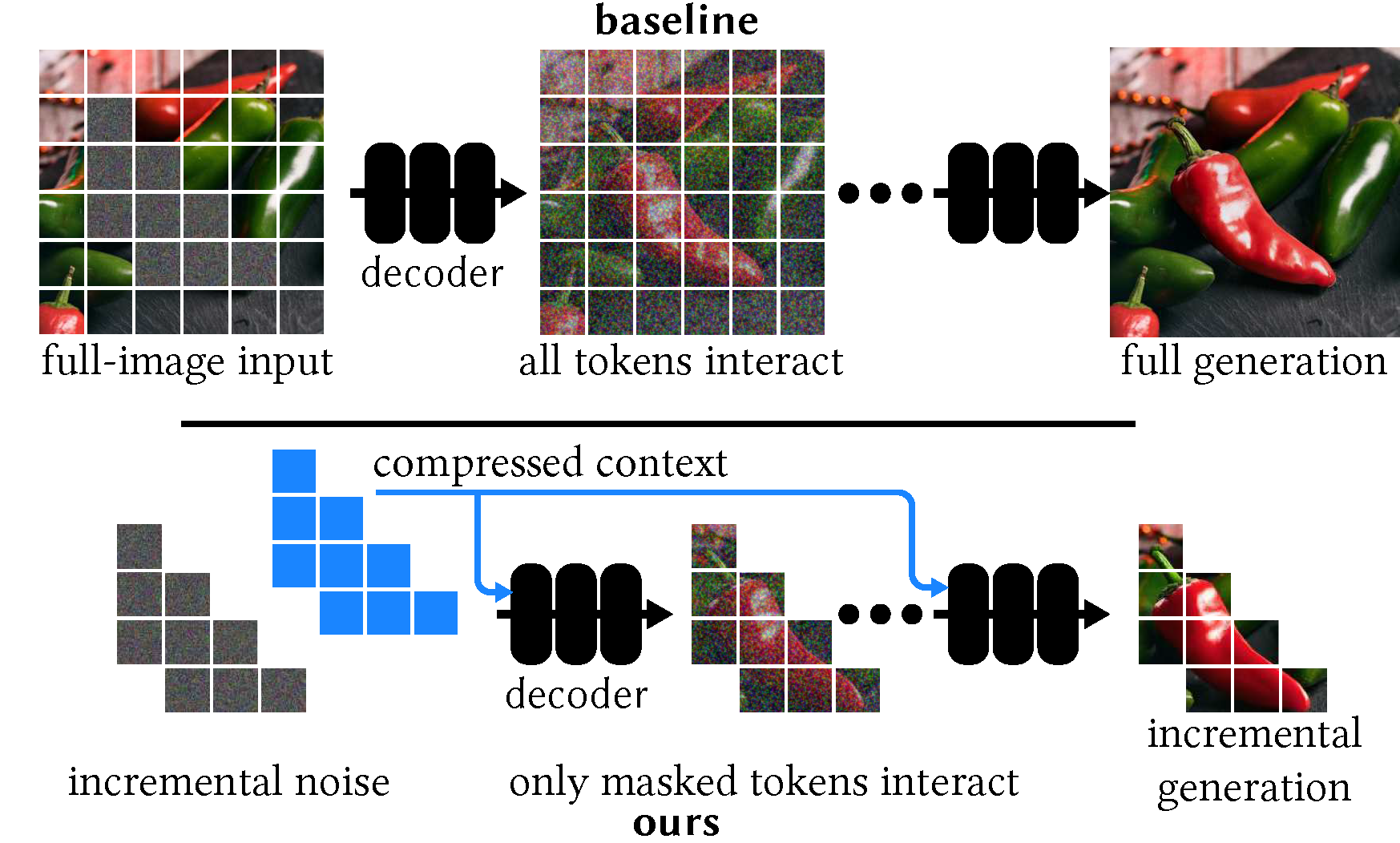
Our diffusion transformer decoder (bottom) reduces synthesis computation using two strategies.
First, we compress the image context using a separate encoder (not shown) outside the diffusion loop.
Second, we only generate tokens corresponding to the masked region to generate.
In contrast, typical diffusion transformers (top) maintain tokens for the entire image throughout the diffusion process,
to preserve global context. When performing inpainting, such model generates a full-size image,
most of which is discarded in order to in-fill the hole region only.
Existing convolutional diffusion models for inpainting suffer from the same drawbacks.
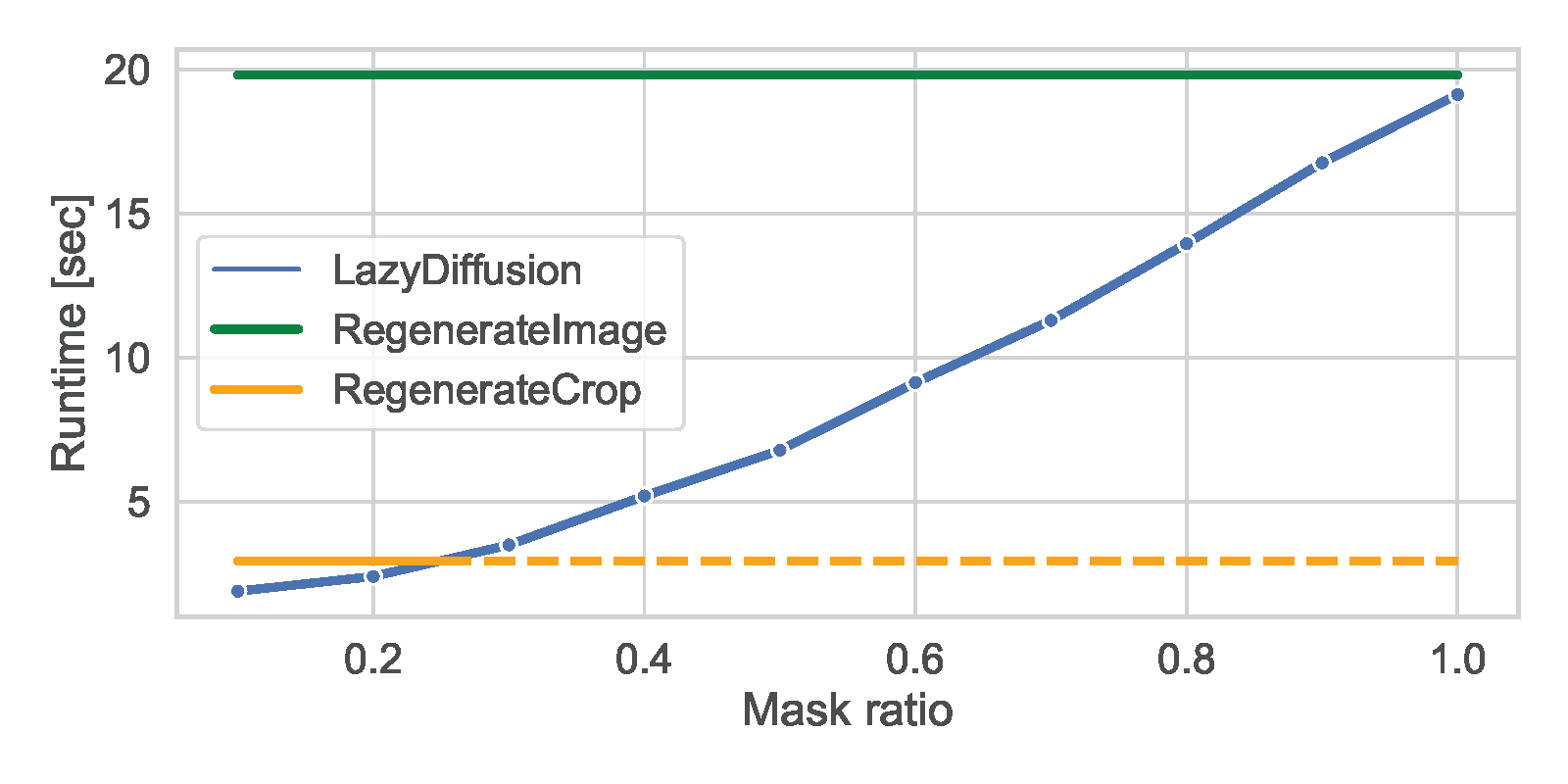
We compare LazyDiffusion to the two existing inpainting approaches -- regenerating a smaller crop or the entire image. All methods are using a PixArt-based architecture. LazyDiffusion is consistently faster than a regenerating the entire image, especially for small mask ratios typical to interactive edits, reaching a speedup of 10x. Similarly, LazyDiffusion is faster than regenerating a crop when the mask is smaller than that. For masks greater than that (dashed), regenerating the crop is technically faster but generates in low-resolution and naively upsamples to match the desired resolution, harming image quality.
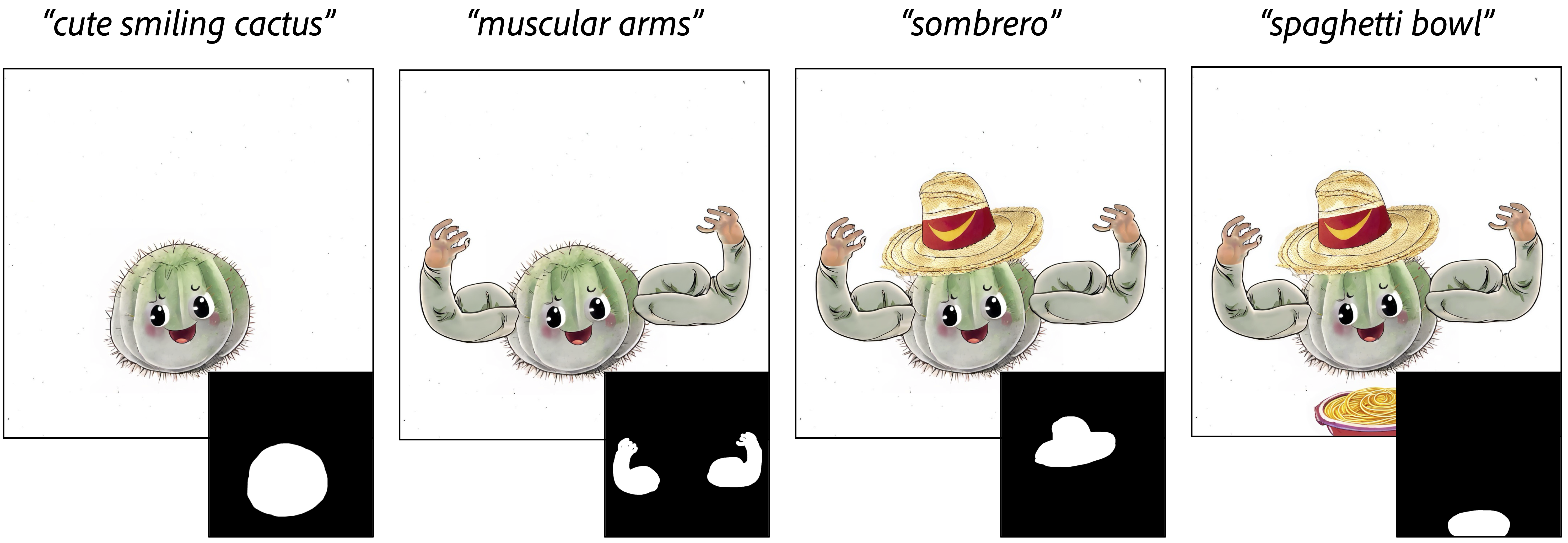
Each panel illustrates a generative progression compared to the preceding state of the canvas to its left.



We compare LazyDiffusion with two models regenerating a 512x512 crop (Stable Diffusion 2 and a PixArt-inpainting model)
and two models regenerating the entire 1024x1024 image (Stable Diffusion XL and a second PixArt-inapinting model).
When inpainting objects that require relatively little semantic context, all methods produce reasonably good results

When inpainting an object closely related to others, the inpainting model requires robust semantic understanding. Methods processing only a crop produce objects that may seem reasonable in isolation, but do not fit well within the greater context of the image. In contrast, LazyDiffusion leverages the compressed image context to generate high-fidelity results, comparable in quality to models regenerating the entire image and running up to ten times slower.

@misc{nitzan2024lazy,
title={Lazy Diffusion Transformer for Interactive Image Editing},
author={Yotam Nitzan and Zongze Wu and Richard Zhang and Eli Shechtman and Daniel Cohen-Or and Taesung Park and Michaël Gharbi},
year={2024},
eprint={2404.12382},
archivePrefix={arXiv},
primaryClass={cs.CV}
}